
A Price Index Could Clarify Opaque GPU Rental Costs for AI
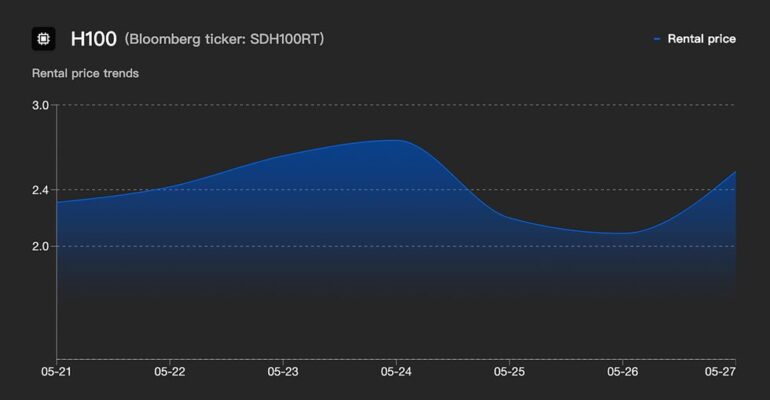

Ask what—if anything—is holding back the AI industry, and the answer you get depends a lot on who you’re talking to. I asked one of Bloomberg’s former chief data wranglers Carmen Li, and her answer was “price transparency.”
According to Li, the inability of most of the smaller AI companies to predict how much they will need to spend for the privilege of renting time on a GPU to train their models makes their businesses unpredictable and has made financing AI companies unnecessarily expensive. She founded the startup Silicon Data to create a solution: the first worldwide rental price index for a GPU.
That rental price index, called the SDH100RT, launched today. Every day, it will crunch 3.5 million data points from more than 30 sources around the world to deliver an average spot rental price for using an Nvidia H100 GPU for an hour. (“Spot price” is what a commodity to be delivered immediately sells for right now.)
“I really believe compute will be the biggest resource for humanity in the next few years,” says Li. “If my thesis is right, then it will need more sophisticated risk management.”
According to Li, such an index will lead to cheaper AI tools and more opportunities for a wider set of players to get involved in the AI industry. How do you get from an index to all that? Silicon Data’s origin story helps explain it.
US $1.04: Rental price advantage for Nvidia H100 GPUs on the East Coast of the United States versus those on the West Coast.
Until early last year, Li was in charge of global data integration at Bloomberg. In that position she met with several small companies that were trying to deliver AI-fueled data products, and many of them were struggling with the same problem. They could only offer their product at a fixed rate, but the cost of the GPU time they needed was unpredictable. Therefore, so were their profit margins.
With typical commodities like energy, companies can plan for these swings by knowing historical trends and hedging with financial products like futures contracts. But that didn’t exist for AI’s main commodity: time on a GPU. So Li set out to create the foundation for those products, and the result is the SDH100RT price index.
She chose to index the Nvidia H100, because it’s the most widely deployed GPU, and it’s used to train new AI models. However, a price index for Nvidia A100s, which tackle a lot of inference tasks, is in the works as well. And she’s developed a method that will determine when it makes sense to index prices for other AI chips, such as those from AMD and Nvidia’s Blackwell series.
 Carmen Li founded Silicon Data after a stint at Bloomberg.Silicon Data
Carmen Li founded Silicon Data after a stint at Bloomberg.Silicon Data
Armed with the data, startups and others building new AI products will be able to understand their potential costs better, so they can set their services at a profitable price. And those building new AI infrastructure will be able to set a benchmark for their own revenue. But just as important, in Li’s opinion, is that new sources of capital can get involved in the AI space.
Banks, for example, are a relatively inexpensive supplier of capital, notes Li. But because they have strict risk controls and there hasn’t been enough GPU price data, they haven’t been in a position to fund AI projects. Li hopes that the SDH100RT will let banks lend to a wider set of players in the AI industry and allow them to come up with financial products that reduce the risk for those already in it.
Insights and Oddities from the Data
Although it launched today, Silicon Data has been tracking GPU rental prices for months. As you might expect, having a window into the price of AI training has unveiled some interesting insights. What follows are a few things Li has discovered. (She’s been publishing these analyses on the regular since last September.)
East Coast rules! West Coast drools: H100 rental pricing is very stable in the United States, but there’s a persistent East Coast advantage. In March you could get an hour of work from an H100 on the East Coast for US $5.76. But that same hour would cost you $6.80 on the West Coast.
Hyperscaler chips help: Amazon Web Services’ foray into designing its own chips and servers has lowered prices for the cloud giant’s customers. According to Silicon Data, at about $4.80 per hour, the average unit price per GPU for AWS’s Trainium2 is less than half the price for using an Nvidia H100. Its first-generation chips Inferentia and Trainium both come in at less than $1.50 per hour, which is less than half the price of today’s inference workhorse, the Nvidia A100. However, H100s are thought to be the only option for cutting-edge model training, so their performance might justify the extra scratch.
DeepSeek’s modest effect: January’s DeepSeek shock did little to the spot rental price. You may recall that the performance and reported low-cost training of Hangzhou-based DeepSeek’s LLMs took many by surprise and sent AI-related stocks into a patch of pearl clutching. “When DeepSeek came out, the [stock] market went nuts,” says Li. “But the spot price didn’t change much.” On DeepSeek’s debut, the H100 price went up mildly to $2.50 per hour, but that was still in the $2.40 per hour to $2.60 per hour range from the months before. It then slid to $2.30 per hour for much of February before it started climbing again.
Intel is more posh than AMD: GPUs are always under the control of CPUs, usually in a 4:1 ratio. And the market for that CPU spot is contested between Intel and AMD. (Nvidia also makes its own CPU, called Grace.) But it seems customers are willing to pay a bit of a premium for Intel-powered systems. For Nvidia A100 systems, those with Intel CPUs fetched about a 40 percent higher price than those with AMD processors. For the H100, the effect depended on the interconnect technology involved. If a computer used SXM or PCIe as its links, Intel fetched a higher price. But for those using Nvidia’s NVLink interconnect scheme, AMD got the premium.
The Commoditization of AI
Can you really boil the price of AI down to a single number? After all, there are so many factors involved in a computer’s performance and its utility to a particular customer. For example, a customer might be training with data that cannot, for legal reasons, cross international borders. So why should they care about the price in another country? And, as anyone who has examined machine learning’s leading benchmark results, MLPerf, can see, the performance of the same Nvidia GPU can vary widely depending on the system it’s in and the software it’s running.
According to Li, the commodity view can work. Silicon Data’s index normalizes all these differences and gives different weights to things like how much a data center participates in the rental market, its location, its data sources, and many, many other things.
Perhaps the biggest endorsement of the idea of AI as a commodity is from Nvidia CEO Jensen Huang himself. At the company’s big developer event, GTC, he pushed for thinking of data centers as “AI factories” whose output would be measured in how many tokens, the smallest unit of information an LLM uses, they can produce per second.
Ask what—if anything—is holding back the AI industry, and the answer you get depends a lot on who you’re talking to. I asked one of Bloomberg’s former chief data wranglers Carmen Li, and her answer was “price transparency.”According to Li, the inability of most of the smaller AI companies to predict how much they will need to spend for the privilege of renting time on a GPU to train their models makes their businesses unpredictable and has made financing AI companies unnecessarily expensive. She founded the startup Silicon Data to create a solution: the first worldwide rental price index for a GPU.That rental price index, called the SDH100RT, launched today. Every day, it will crunch 3.5 million data points from more than 30 sources around the world to deliver an average spot rental price for using an Nvidia H100 GPU for an hour. (“Spot price” is what a commodity to be delivered immediately sells for right now.)“I really believe compute will be the biggest resource for humanity in the next few years,” says Li. “If my thesis is right, then it will need more sophisticated risk management.”According to Li, such an index will lead to cheaper AI tools and more opportunities for a wider set of players to get involved in the AI industry. How do you get from an index to all that? Silicon Data’s origin story helps explain it.US $1.04: Rental price advantage for Nvidia H100 GPUs on the East Coast of the United States versus those on the West Coast.Until early last year, Li was in charge of global data integration at Bloomberg. In that position she met with several small companies that were trying to deliver AI-fueled data products, and many of them were struggling with the same problem. They could only offer their product at a fixed rate, but the cost of the GPU time they needed was unpredictable. Therefore, so were their profit margins.With typical commodities like energy, companies can plan for these swings by knowing historical trends and hedging with financial products like futures contracts. But that didn’t exist for AI’s main commodity: time on a GPU. So Li set out to create the foundation for those products, and the result is the SDH100RT price index. She chose to index the Nvidia H100, because it’s the most widely deployed GPU, and it’s used to train new AI models. However, a price index for Nvidia A100s, which tackle a lot of inference tasks, is in the works as well. And she’s developed a method that will determine when it makes sense to index prices for other AI chips, such as those from AMD and Nvidia’s Blackwell series. Carmen Li founded Silicon Data after a stint at Bloomberg.Silicon DataArmed with the data, startups and others building new AI products will be able to understand their potential costs better, so they can set their services at a profitable price. And those building new AI infrastructure will be able to set a benchmark for their own revenue. But just as important, in Li’s opinion, is that new sources of capital can get involved in the AI space.Banks, for example, are a relatively inexpensive supplier of capital, notes Li. But because they have strict risk controls and there hasn’t been enough GPU price data, they haven’t been in a position to fund AI projects. Li hopes that the SDH100RT will let banks lend to a wider set of players in the AI industry and allow them to come up with financial products that reduce the risk for those already in it.Insights and Oddities from the DataAlthough it launched today, Silicon Data has been tracking GPU rental prices for months. As you might expect, having a window into the price of AI training has unveiled some interesting insights. What follows are a few things Li has discovered. (She’s been publishing these analyses on the regular since last September.)East Coast rules! West Coast drools: H100 rental pricing is very stable in the United States, but there’s a persistent East Coast advantage. In March you could get an hour of work from an H100 on the East Coast for US $5.76. But that same hour would cost you $6.80 on the West Coast.Hyperscaler chips help: Amazon Web Services’ foray into designing its own chips and servers has lowered prices for the cloud giant’s customers. According to Silicon Data, at about $4.80 per hour, the average unit price per GPU for AWS’s Trainium2 is less than half the price for using an Nvidia H100. Its first-generation chips Inferentia and Trainium both come in at less than $1.50 per hour, which is less than half the price of today’s inference workhorse, the Nvidia A100. However, H100s are thought to be the only option for cutting-edge model training, so their performance might justify the extra scratch.DeepSeek’s modest effect: January’s DeepSeek shock did little to the spot rental price. You may recall that the performance and reported low-cost training of Hangzhou-based DeepSeek’s LLMs took many by surprise and sent AI-related stocks into a patch of pearl clutching. “When DeepSeek came out, the [stock] market went nuts,” says Li. “But the spot price didn’t change much.” On DeepSeek’s debut, the H100 price went up mildly to $2.50 per hour, but that was still in the $2.40 per hour to $2.60 per hour range from the months before. It then slid to $2.30 per hour for much of February before it started climbing again.Intel is more posh than AMD: GPUs are always under the control of CPUs, usually in a 4:1 ratio. And the market for that CPU spot is contested between Intel and AMD. (Nvidia also makes its own CPU, called Grace.) But it seems customers are willing to pay a bit of a premium for Intel-powered systems. For Nvidia A100 systems, those with Intel CPUs fetched about a 40 percent higher price than those with AMD processors. For the H100, the effect depended on the interconnect technology involved. If a computer used SXM or PCIe as its links, Intel fetched a higher price. But for those using Nvidia’s NVLink interconnect scheme, AMD got the premium.The Commoditization of AICan you really boil the price of AI down to a single number? After all, there are so many factors involved in a computer’s performance and its utility to a particular customer. For example, a customer might be training with data that cannot, for legal reasons, cross international borders. So why should they care about the price in another country? And, as anyone who has examined machine learning’s leading benchmark results, MLPerf, can see, the performance of the same Nvidia GPU can vary widely depending on the system it’s in and the software it’s running.According to Li, the commodity view can work. Silicon Data’s index normalizes all these differences and gives different weights to things like how much a data center participates in the rental market, its location, its data sources, and many, many other things.Perhaps the biggest endorsement of the idea of AI as a commodity is from Nvidia CEO Jensen Huang himself. At the company’s big developer event, GTC, he pushed for thinking of data centers as “AI factories” whose output would be measured in how many tokens, the smallest unit of information an LLM uses, they can produce per second.











